Speed Up XML Parsing With CGO
Overview
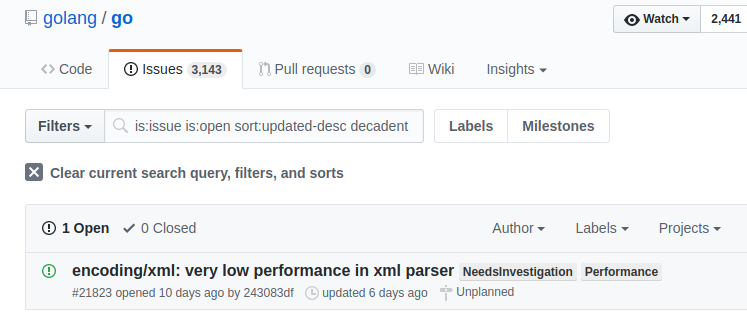
There was an interesting Go issue raised on Github in September 2017. Interesting and funny at the same time. The issue initiator used the word decadent to describe the performance of the Go XML reader, in comparison with, say, C#. I don't know why, but I found that characterization very amusing, and (sadly) rather accurate.
It does appear to be the only mention of decadence within the Golang official repositories so far. Not surprisingly; "The Flowers of Evil" are not within the graces of a language that eschews needless sophistication.
While I had worked with Go and XML before, in production environments, it mainly involved receiving legacy data through network streaming, where manageable content chunk sizes and inherent I/O latencies were the primary culprits, trumping the need to reach for the benchmarking magnifying glass. The use case presented in the issue referred to reading over the content of medium-sized and large-sized files, over 200Mb, accessible from local disk.
I did work with streaming-based XML parsers in C# and Java and I knew them to be mature and speedy, but the extent of their performance advantage surprised me.
This article details a few superficial benchmarking in several languages, to understand where we're at now, as well as an equally superficial attempt to implement a cgo-based parsing alternative to the native Go one.
A Case For Benchmarking
In my opinion, unlike countless artificial scenarios, the performance penalty mentioned in the issue is a valid case of concern. For statistics-heavy applications, that work with millions of data points in memory, the expectation is there for data to get loaded as quickly as possible.
A valid, real-life scenario could entail a massive XML file with recent tick data of various financial instruments. An initial parser would weed out the unnecessary instruments and load only the targeted ones in memory, where projections, automated trading recommendations, and many other financial machiavellianisms would take place.
For benchmarking purposes, I opted for a more mundane scenario: the generated XML file would contain some pseudo-real estate info, with buildings of various types. I ended up with a 270M file of randomly generated "House", "Mansion", "Bungalow", "Villa" and "Apartment" elements. Each element has tree other attributes perched inside:
<?xml version="1.0" encoding="utf-8"?>
<Catalogue>
<Villa type="Detached" price="260387" status="Unavailable" />
<House type="Detached" price="92820" status="Unavailable" />
...
<Apartment type="Detached" price="204603" status="Sold" />
<Mansion type="Semidetached" price="322513" status="Available" />
...
The generator code:
var elemTypes = [...]string{"House", "Mansion", "Bungalow", "Villa", "Apartment"}
var subElemTypes = [...]string{"Detached", "Semidetached"}
var statusType = [...]string{"Available", "Sold", "Unavailable"}
// ...
s1 := rand.NewSource(time.Now().UnixNano())
r1 := rand.New(s1)
f.WriteString("<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<Catalogue>\n")
for i := 0; i < numElements; i++ {
randMainType := r1.Intn(len(elemTypes))
randSubElemType := r1.Intn(len(subElemTypes))
randStatusType := r1.Intn(len(statusType))
randPrice := strconv.Itoa(40000 + r1.Intn(300000))
elem := fmt.Sprintf("<%s type=\"%s\" price=\"%s\" status=\"%s\" />\n",
elemTypes[randMainType], subElemTypes[randSubElemType],
randPrice, statusType[randStatusType])
if _, err := f.WriteString(elem); err != nil {
log.Println("Element write error: ", err)
return
}
//...
}
f.WriteString("</Catalogue>\n")
Benchmarking Rules of Engagement
The intent is to offer all benchmarked languages as much of a level playing field as possible, so I thought of preallocating an array of 900 thousand House items (where House is a custom struct), then start the parser and populate the array with House elements exclusively (there were about 899 thousand in my generated file). I'm only measuring the for...loop:
type House struct {
Type string `xml:"type,attr"`
Price string `xml:"price,attr"`
Status string `xml:"status,attr"`
}
// ...
var houseArray [900000]House
// ...
start := time.Now()
for {
token, err := decoder.Token()
if err == io.EOF {
break
}
switch tt := token.(type) {
case xml.StartElement:
if tt.Name.Local == "House" {
h := House{Type: tt.Attr[0].Value, Price: tt.Attr[1].Value, Status: tt.Attr[2].Value}
houseArray[totalItemsProcessed] = h
totalItemsProcessed = totalItemsProcessed + 1
}
}
}
elapsed := time.Since(start)
fmt.Printf("DONE. Total items found and processed: %d\n", totalItemsProcessed)
fmt.Printf("Total time: %s\n", elapsed)
The results eventually appeared:
$ ./xmlbench
No profiling enabled via flags. Initiating xml reader benchmarking.
Searching for: House...DONE. Total items found and processed: 899004
Total time: 11.868717969s
Ok... 11 to 12 seconds. Fair enough, but before we cry "wolf", let's see how other languages cope with the XML parse and import task.